はじめに
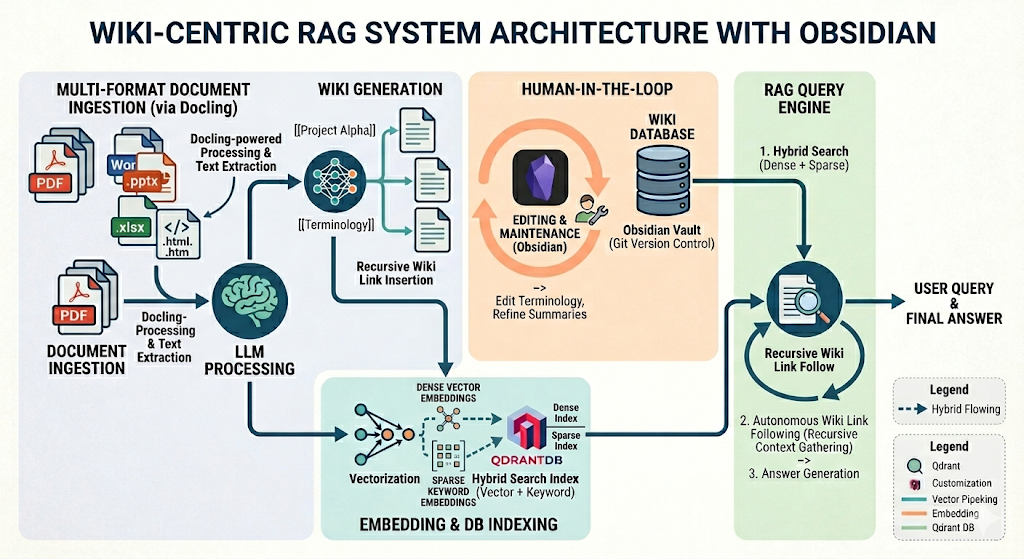
雑多なドキュメントをRAGで利用する場合、ノイズ除去や要約といった前処理が不可欠です。しかし、一度DBに入れてしまうと、その後の更新や誤りの修正が面倒になるという課題があります。 そこで、「LLMにWiki風Markdownを生成させ、それをObsidianで人間がメンテナンスする」というフローを試してみました。
Wiki形式は便利かも
-
メンテナンス性: LLMによる抽出が間違っていても、Obsidianで直接編集してDBに即座に反映できる。
-
自己完結: RAGを動かさずとも、Wikiを眺めるだけで解決することも多い。
-
ポータビリティ: Markdownなので、他の便利ツールをすぐに使えるかも。
システムの構成
-
データの構築: LLMを用いてドキュメントから「ページ内容」と「用語集(Wikiリンク付き)」を抽出。
-
DB: ハイブリッド検索(ベクトル+キーワード)用に Qdrant を採用。
-
インターフェース: Obsidian を使用。編集内容はGit経由での差分管理やDB更新のトリガーに利用。
「自律追跡型」RAG検索エンジン
検索アルゴリズムもWikiを活かします。
-
初期検索: Qdrantからクエリに関連するテキストを抽出。
-
再帰的展開: 抽出されたドキュメント内の「Wikiリンク(例:
[[用語]])」を検出し、その解説ページもコンテキストに自動で継ぎ足す。 -
回答生成: 関連知識が網羅されたリッチなコンテキストをもとに回答。
RAGの検索方法はいろいろな手があると思います。目的に応じて組み替えればよいので気楽です。また、wiki自体はmarkdownなので、様々なツールに放り込めるというのも利点です。
終わりに
とりあえず動作させてみて遊んでいます。gitを使ったwiki更新の差分管理も入れ込んだりしています。まだ雑なのでポチポチ進めてみようと思っています。もう、こんなアプリありそうですけど。
図:Gemini(nano banana2)で作成
論文から生成させたページ
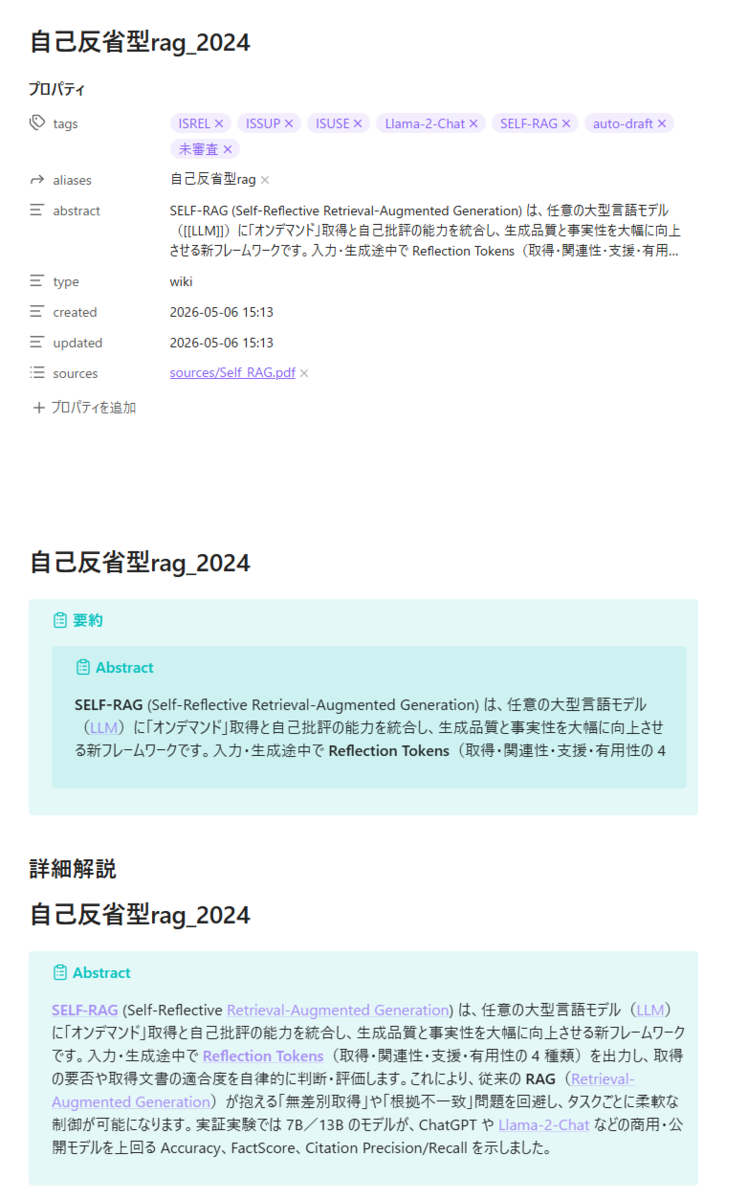
"SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION" Akari Asaiら
用語ページ

グラフビュー例
RAGの回答例
uv run python main.py --query "CRAGにおけるCorrectとIncorrectの違い、およびWeb Searchの役割は何ですか?
CRAG における「Correct」-「Incorrect」の違い
Correct(正確): 取得文書がクエリに適合し生成タスクに有用な状態。軽量評価器(T5-large)が閾値 τ_up 以上と判定した際に発動し、そのまま生成部に渡される。
Incorrect(不正確): 取得文書の適合度が低く、ノイズや誤情報を含む状態。評価スコアが閾値 τ_low 以下の時に判定され、静的コーパスを放棄して外部 Web 検索が実行される。
Web Search の役割代替知識の取得: 判定が「Incorrect」または「Ambiguous」となった際、Google Search API を経由して動的に外部から関連文書を補正取得する。
クエリの書き換え: 質問から ChatGPT 等を介して最適化されたキーワードクエリを自動生成し、ノイズを抑えた検索を実行する。
知識の精錬: 取得したWebページを「decompose-then-recompose」で文単位に分解、評価器で再フィルタリングして最も純度の高い知識として統合する。(略)