詳しい記事があったので、気になっていたHybrid Searchを試した。
参考記事
www.jiang.jp
FAISSと同じだろうと思いつつChromaも評価用のコードに加えました。embeddingモデルはmultilingual-e5-largeを使いました。
from langchain.vectorstores import FAISS
from langchain.vectorstores import Chroma
# from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.retrievers import KNNRetriever
from langchain.retrievers import SVMRetriever
from langchain.retrievers import TFIDFRetriever
from langchain.retrievers import ElasticSearchBM25Retriever
embedding = HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-large"
)
# Vectorstore
faiss_vectorstore = FAISS.from_texts(documents, embedding)
chroma_vectorstore = Chroma.from_texts(documents, embedding)
svm_retriever = SVMRetriever.from_texts(documents, embedding)
svm_retriever.k = DOC_NUM
# Evaluate
# Faiss
faiss_similarity_result = evaluate(query_list, lambda q: faiss_vectorstore.similarity_search(q, k=DOC_NUM))
faiss_mmr_result = evaluate(query_list, lambda q: faiss_vectorstore.max_marginal_relevance_search(q, k=DOC_NUM))
# Chroma
chroma_similarity_result = evaluate(query_list, lambda q: chroma_vectorstore.similarity_search(q, k=DOC_NUM))
chroma_mmr_result = evaluate(query_list, lambda q: chroma_vectorstore.max_marginal_relevance_search(q, k=DOC_NUM))
# SVM
svm_result = evaluate(query_list, lambda q: svm_retriever.get_relevant_documents(q))
result_df = pd.DataFrame(
[
["faiss_similarity", faiss_similarity_result.mrr, faiss_similarity_result.recall_at_1, faiss_similarity_result.recall_at_5],
["faiss_mmr", faiss_mmr_result.mrr, faiss_mmr_result.recall_at_1, faiss_mmr_result.recall_at_5],
["chroma_similarity", chroma_similarity_result.mrr, chroma_similarity_result.recall_at_1, chroma_similarity_result.recall_at_5],
["chroma_mmr", chroma_mmr_result.mrr, chroma_mmr_result.recall_at_1, chroma_mmr_result.recall_at_5],
["svm", svm_result.mrr, svm_result.recall_at_1, svm_result.recall_at_5],
],
columns = ["model_id","mrr","recall_at_1","recall_at_5"]
).sort_values("mrr", ascending=False)
結果
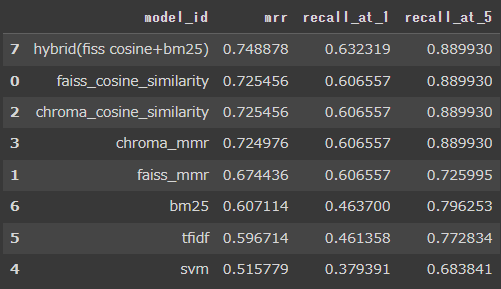
記事通りにHybridが良い。faissとchromaは大きな違いはないだろうとおもったが、mmrについてはFaissとchrmaの大きく異なる結果になった。気になるくらい大きな差だ。試して見て良かった。個々の部分は、たまたま当方のスクリプトの問題かもしないけれども、気に留めておくことにする。
