Whisperをブラウザ上で使えるwhisper-webをお試ししたくて、dockerで構築しました。利用するときには、デフォルトが日本語じゃないし、設定が分かりにくいかもしれません。現在のところ、whisper-large v3 turboを利用するためにはWebGPU版の実験ブランチ版を使うとよいようです。
2時間半くらいの長い音声録音データを放り込んでみました。残念ながらGPUを使ってはいるものの、GPU利用率も上がらず速度はでません。時々、急に速度があがったり、プチフリ状態になったりです。ファイルが大きすぎたのかも・・・。もちろん、whisper-large v3 turboは精度は悪くありません。まだ、実験的な実装のようなので、これから調整が進んでいくのではないかと期待しています。
WebGPUもモデルファイルのキャッシングがブラウザと連携が取れるようになってくると普通に使われる技術になるのでしょうか。
今回のDockerでの動作手順
Dockerfileを作成します。
# 使用するベースイメージ
FROM node:18# ワークディレクトリ
WORKDIR /appRUN git clone https://github.com/xenova/whisper-web.git
WORKDIR /app/whisper-web
# パッケージをインストール
RUN npm install
# アプリケーション
RUN npm run build# シンプルサーバ
RUN npm install -g serve# ポートを指定
EXPOSE 5173# Define the command to run the app
CMD ["serve", "-s", "dist", "-l", "5173"]
WebGPU対応版はbranch experimental-webgpuです。Dockerfileは以下にするとwhisper-large v3 turboが使えます。最初のモデルのロード時間が結構かかりますね。最初の一回だけですが。
Dockerfile
# 使用するベースイメージ
FROM node:18# ワークディレクトリ
WORKDIR /app# RUN git clone https://github.com/xenova/whisper-web.git
RUN git clone -b experimental-webgpu https://github.com/xenova/whisper-web.git
WORKDIR /app/whisper-web
# パッケージをインストール
RUN npm install
# アプリケーション
RUN npm run build# シンプルサーバ
RUN npm install -g serve# ポートを指定
EXPOSE 5173# Define the command to run the app
CMD ["serve", "-s", "dist", "-l", "5173"]
Buildします。
docker build --pull --rm -f "Dockerfile" -t whisperweb "."
起動します。
docker run --rm -it -p 5173:5173/tcp whisperweb
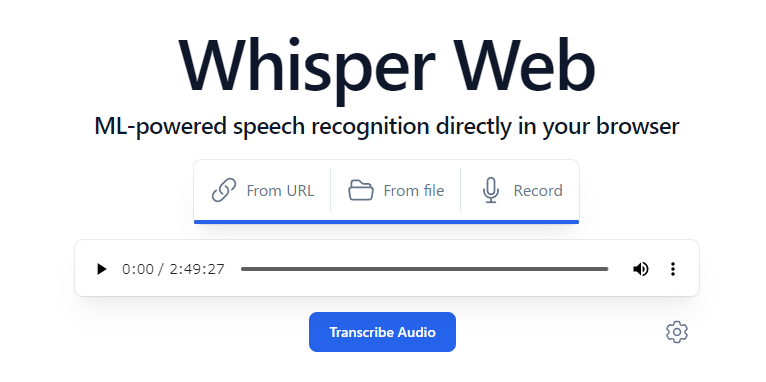
音声ファイルをUploadしたら、右下の歯車でモデルや言語をちゃんと設定して、Transcribe Audioをクリックします。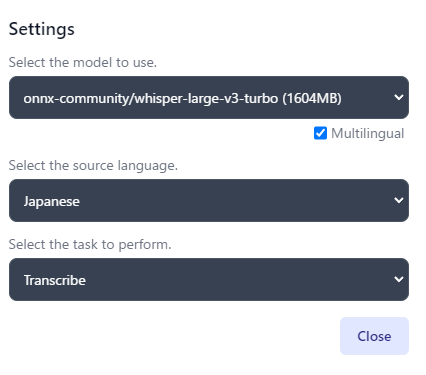
もちろん、最新のバージョンに更新したい時は、buildしなおせば良いので楽ちんです。お手軽に文字おこしができます。