Chatにおけるメモリー機能の記事を読みました。RAGを使わない、というよりも、検索を伴うRAGに適さない基軸的な情報を用意しておく必要があるのでしょう。要は、LLMに投入するプロンプト(コンテキスト)中にメモリー機能とする情報を含ませておく、という理解をしました。
手を動かしてみます。Gemini君やChatGPT君を使いながら理解・議論を進めた後に実装手順を考えて、julesなどを利用しながら実装を進めました。
一連の記事で提案されているのは、以下の4層の記憶を持たせるということです。
Layer 1: ephemeral session metadata
Layer 2: Explicit Long-Term facts
Layer 3: lightweight conversation summaries
Layer 4: Sliding Window Messages
この考え方を咀嚼し、会話じゃなくて議論版に変えてみます。もちろん、単にこのまま実装するのは面白くないから・・・です。
そこで以下の4層とします。
Layer 1: Ephemeral Session Context
Layer 2: Explicit Long-Term Memory
Layer 3: Decision Digest
Layer 4: Sliding Window Messages
議論では決定事項(前提事項)をひっくり返されるとイラっとします。そこで、決定事項のダイジェストをメモリーとして持つことにします。
Layer 1: Ephemeral Session Context については、今の時刻やUIで選択した内容を設定します。Layer 2: Explicit Long-Term Memory、Layer 3: Decision Digestについては、LLMでチャットに応じて投入する動的な内容。Layer 4: Sliding Window Messages は直近の会話履歴としました。概念的には4層メモリーを参考に、4つのコンテキストを配置します。
LLMの使い方としては会話の生成と、Layer2,4の生成の2つを担ってもらいます。LLMはollamaを使ってgemma3:12b-it-qatを利用します。
例えば、健康に関して議論すると以下の様な内容が登録されました。
Explicit Long-Term Memory
健康への関心 ユーザーは健康に非常に高い関心を持っている。
Decision Digest
過剰なストレッチを避ける
回答例。チャット履歴に具体的なサプリメントの種類を入れてありませんが、「ビタミンB群の摂取を決定」というDecision Digestを参照して、ビタミンBという具体的な情報を盛り込んでいます。LTMには「一般的なストレッチ回数は、各ストレッチを10回~15回程度、1~3セット行うのが目安。」という過去の会話での記録が記録されていました。それらを反映した回答となっています。

もちろん、Long-Term Memory やDecision Digestを保存する決定をするプロンプトはチューニングする必要があるでしょうし、これらの記憶を選択して残していく部分は未実装です。この辺りをしっかり実装し、ユーザー毎にデータを保存するように永続化を変更する必要はあります。
議論の一貫性や、仮説を含む決定事項を常にプロンプトに組み込むテクニックは効果的だろうな、という感触を掴むことができました。やはり、プロンプト・・・というより、コンテキストのデザインと言うべきでしょうか。
LLMの呼び出し回数も+1で済みますし、シンプルな方法で効果も高そうな印象でした。ロールプレイングで議論させるエージェントで遊んでみるのも面白そうです。今後、このようなケースに組み込まれる手法の一つなのでしょう。
最後に引き続きgemma3:12bでお試し。雑談の相手にはぴったり?
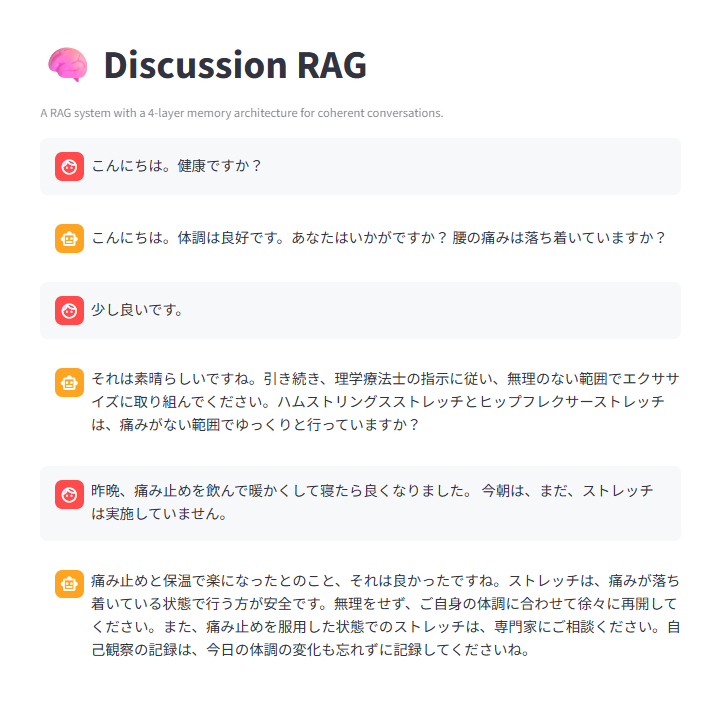
体は大事にしましょう。
お試しおわり。