色んなデータを素人でも入手できるようになって、時系列を予測に用いる外生変数として用いるデータの入手して勉強する題材とするには事欠かない。だからといって、なんでもかんでも導入するのはよろしくない。過剰に適合するだけではなく、一番大事な予測したモデルやトレンドや季節性といった肝心な解析の解釈がおざなりになる。
そこで、予め手元にあるデータのクラスタリングを行ってみて、外生変数候補データをざっくり分類して眺めてみる。データを俯瞰してみる手段として時系列クラスタリングにチャレンジです。
利用するのはtslearn(BSD-2-Clause license)です。
クラスタリングでは似ているデータを寄せていきます。この時、時系列データにおいて「似ている」というのはどういうことかという問題が発生します。少し時間がズレただけで似ている波形はあるはずです。単純に2つの時系列の波の差分だけでは評価できません。
今回用いるtslearnでは、ラグも考慮した外生変数の抽出を見ていきたいので、動的時間伸縮法DTW(Dynamic Time Warping)を使ったクラスタリングにチャレンジしました。このライブラリではEuclideanによるクラスタリングも可能です。簡潔にまとめていらっしゃる方の記事を参照してください。
以下の前提でプログラムしてみました。
- sampledataは、yfinanceからダウンロードしてきた色んな企業の株価を用います。
- 株価データは、最小最大で正規化して用います。
- クラスタリング数は、エルボー法とシルエット法で評価して決めます。今回は味見なので、クラスター数は単純に多い方を採用します。
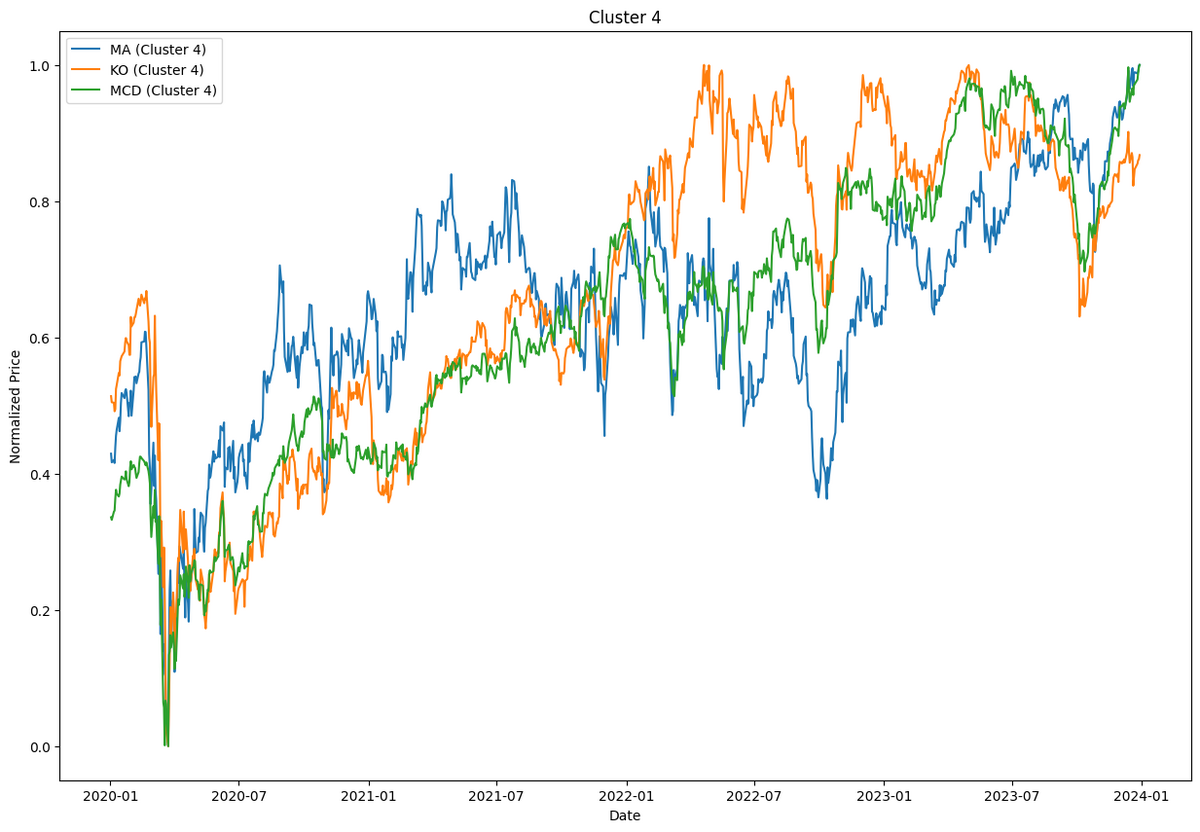
結果は以下の様になりました。Cluster0が混雑しちゃっていますが、それなりには分離できているようです。
簡単なクレスタリングだけでは実際の解釈までに至りませんが、株価指数と比較して同じクラスターに属する銘柄はどれなのか・・・くらいは簡単にできそうです。




今回、作成したColabのノート。